



Dans le contexte de la crise liée au Covid-19, il est devenu essentiel pour les entreprises de pouvoir compter les personnes présentes dans un lieu et de s’assurer de la distanciation sociale.
Nous voulons créer un moyen permettant de comptabiliser des personnes qui entrent dans un bâtiment ou qui sont présentes dans un lieu — par exemple une cantine d’entreprise — via le flux vidéo d’une caméra. De plus, nous voulons détecter si ces personnes portent un masque.
Pour répondre à ce besoin, nous allons utiliser un Framework de détection d’objets construit sur les technologies suivantes : TensorFlow, Keras et OpenCV.
Architecture du système

Librairies python
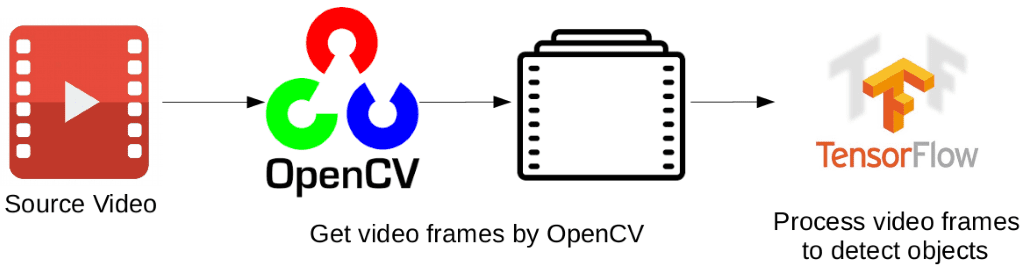
À partir d’une source vidéo, nous allons utiliser la librairie OpenCV (https://github.com/opencv/opencv) pour lire cette vidéo et la découper en différents frames. C’est à partir de ces frames que l’on va pouvoir détecter des objets sur la vidéo. En effet, les modèles de machine learning pour la détection et la classification d’objet fonctionnent sur des images issues de la vidéo.
Chaque frame est alors traité par un modèle de détection développé sur TensorFlow (https://github.com/tensorflow/tensorflow) qui après entrainement détectera les personnes et la présence de masque sur chaque frame de la vidéo.
La logique de fonctionnement est indiquée sur la figure ci-dessous :
Modèles de Machine Learning
Quelle méthode est utilisée pour détecter les personnes sur la vidéo ?
Chaque fois que nous parlons de détection d’objets, nous parlons principalement de ces méthodes de détection primaires :
- Faster RCNN
- Single-shot detection (SSD)
- You look only once (YOLO)
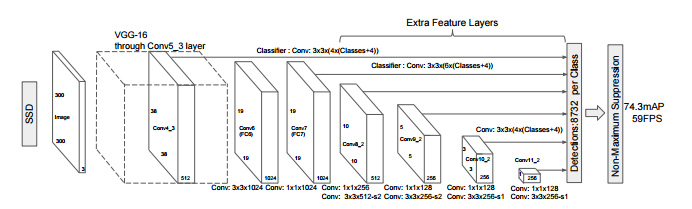
SSD a été développé par les équipes de chercheurs de Google pour maintenir l’équilibre entre les deux méthodes de détection d’objets que sont YOLO et RCNN.
La détection d’objet SSD prend une seule photo pour détecter plusieurs objets dans l’image.
Il se compose de deux parties :
- Extraire des cartes d’entités et
- Appliquer un filtre de convolution pour détecter les objets
Le SSD est plus rapide que R-CNN, car dans R-CNN, nous avons besoin de deux plans, un pour générer des propositions de région et un pour détecter des objets, alors que dans SSD, cela peut être fait en un seul coup. Le SSD a aussi une meilleure accuracy que YOLO.
Nous allons utiliser Mobile Net. Les Mobile Nets sont une famille de modèles pré-entrainés de vision par ordinateur pour TensorFlow, conçus pour maximiser efficacement la précision tout en gardant à l’esprit les ressources limitées pour une application intégrée ou sur mobile. Notamment, car il est plus petit et plus rapide que les autres modèles existants.
C’est donc un modèle SSD avec Mobile Net qui a été utilisé dans ce projet. Il est possible d’utiliser d’autres modèles pré-entrainés disponibles prêts à l’emploi avec des vitesses et des précisions variables (https://github.com/tensorflow/models/tree/master/research/object_detection/models). Vous pouvez facilement sélectionner, télécharger et utiliser des modèles de pointe adaptés à vos besoins.
Explication de la méthode
Un modèle de détection d’objets est entraîné pour détecter la présence et l’emplacement de plusieurs classes d’objets. Par exemple, un modèle peut être entraîné avec des images qui contiennent diverses personnes, avec un label qui spécifie la classe qu’ils représentent, et des données spécifiant où chaque objet apparaît dans l’image.
Lorsqu’une image est ensuite fournie au modèle, il génère une liste des objets qu’il détecte, l’emplacement d’un cadre englobant contenant chaque objet et un score qui indique la certitude que la détection était correcte.
Pour interpréter ces résultats, nous pouvons regarder le score et l’emplacement de chaque objet détecté. Le score est un nombre entre 0 et 1 qui indique la certitude que l’objet a été réellement détecté. Plus le nombre est proche de 1, plus le modèle est confiant.
Pour chaque objet détecté, le modèle renvoie un tableau de quatre nombres représentant un rectangle englobant qui entoure sa position. La valeur supérieure représente la distance entre le bord supérieur du rectangle et le haut de l’image, en pixels. La valeur de gauche représente la distance entre le bord gauche et la gauche de l’image d’entrée. Les autres valeurs représentent les bords inférieur et droit de la même manière.
Il est aussi possible d’effectuer un apprentissage par transfert sur des modèles TensorFlow entraînés (https://www.tensorflow.org/tutorials/images/transfer_learning) pour créer vos systèmes de comptage d’objets personnalisés. C’est ce que j’ai fait pour la détection de masque.
En effet, nous avons utilisé Transfert learning avec le modèle MobileNetV2 (sans réentraîner les poids) grâce à la librairie de deep learning Keras (https://github.com/keras-team/keras) Il a suffi d’ajouter deux nouvelles couches à la tête du modèle permettant à ce modèle pré-entrainé de reconnaître et appliquer des connaissances et des compétences, apprises à partir de tâches antérieures, sur de nouvelles tâches ou domaines partageant des similitudes.
Nous avons ensuite combiné ce modèle avec HaarCascadeFrontalFace qui va permettre une détection rapide du visage (https://github.com/opencv/opencv/tree/master/data/haarcascades).
La méthode des cascades de Haar a été proposée en 2001 dans un article de recherche intitulé « Rapid Object Detection using a boosted cascade of simple feature » par Paul Viola et Michael Jones. Elle est rapidement devenue célèbre, car en plus d’obtenir un taux de succès relativement élevé sur des jeux de données difficiles « MIT+CMU Dataset », elle était 15 fois plus rapide que les autres méthodes de détection de visage à l’époque.
Le terme cascade dans le nom du classificateur signifie qu’il est le résultat de plusieurs classificateurs plus simples qui sont appliqués successivement sur une région d’intérêt jusqu’à ce qu’un des stages échoue où qu’ils soient tous validés. L’idée est de rejeter les zones ne contenant pas l’objet avec le moins possible de calculs. Le premier classificateur est donc le plus optimisé et permet de rejeter rapidement une zone si l’objet recherché ne s’y trouve pas. Si potentiellement l’objet s’y trouve, alors le deuxième classificateur est utilisé et ainsi de suite jusqu’au dernier.
Deux modes d’utilisation
- Cumulative Counting Mode : pour détecter, suivre et compter les piétons après qu’ils sont passés par notre région d’intérêt représentée par une ligne tracée à une certaine distance en pixel.


Il suffit de lancer le script principal pour le comptage « pedestrian_counting.py » avec la commande python pedestrian_counting.py
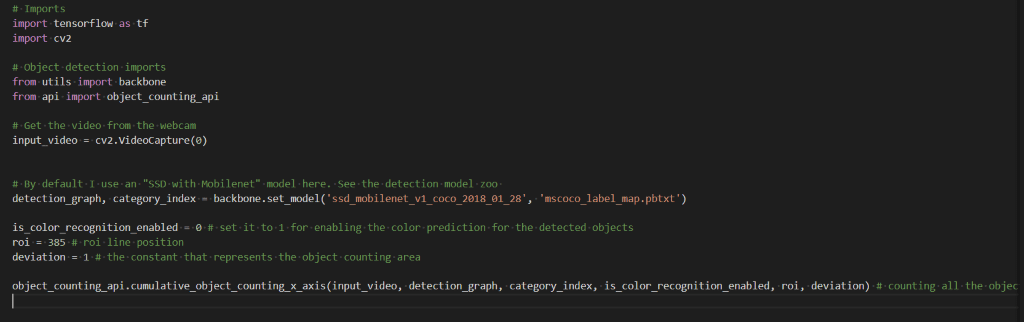
Comme nous pouvons le voir dans le code, pour compter les personnes qui franchissent la ligne, cela va chercher la fonction cumulative_object_counting_x_axis écrite dans le script « object_counting_api.py ».
- Real-Time Counting Mode : pour détecter, suivre et compter l’objet ciblé présent dans le flux vidéo en entier.

Dans ce cas-là, il faut lancer le script « real_time_counting_targeted_object.py » avec la commande python « real_time_counting_targeted_object.py ». Comme on peut le voir dans le code, pour compter les personnes présentes dans la vidéo, cela va chercher la fonction targeted_object_counting écrite dans le script object_counting_api.py.
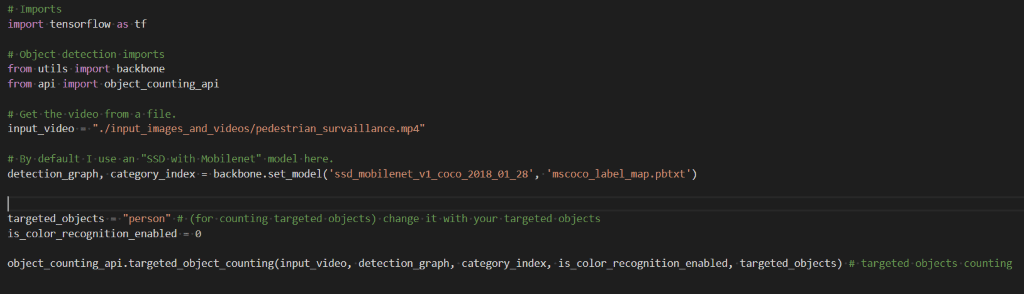
Ces deux fonctions vont alors charger les deux modèles nécessaires pour la détection des personnes et la détection de masque. L’input vidéo sera découpé en frame et chaque frame sera analysé par les modèles qui détecteront les personnes et la présence ou non de masque. Nous pourrons alors visualiser les résultats grâce au script « visualization.py » via les bounding boxes et le texte avec l’aide de la librairie OpenCv (https://docs.opencv.org/master/dc/da5/tutorial_py_drawing_functions.html).
Fonctionnalités générales
Voici quelques fonctionnalités intéressantes de l’API de comptage d’objets TensorFlow :
- Détecter uniquement les objets ciblés
- Détecter tous les objets
- Ne compter que les objets ciblés
- Compter tous les objets
- Imprimer le résultat du comptage de détection dans un fichier .json
- Sélectionner, télécharger et utiliser des modèles de pointe
- Utiliser vos propres modèles entraînés ou un modèle affiné pour détecter des objets spécifiques
- Enregistrer les résultats de détection et de comptage sous forme de nouvelle vidéo ou afficher les résultats de détection et de comptage en temps réel
Points positifs
- Fonctionne en temps réel sur un flux vidéo comme une webcam.
- Cadre évolutif et bien conçu, utilisation facile. Il est assez facile d’implémenter son propre modèle, ou d’utiliser un autre modèle pré entrainé. De même il est possible de détecter d’autres objets en changeant seulement une ligne de code.
- Les avantages de « Pythonic Approach »
Limites
- Besoin de plus de puissance pour fonctionner en temps réel sur des vidéos plus lourdes. Possibilité d’utiliser Tensorflow-GPU (https://www.tensorflow.org/install/gpu?hl=fr) qui comme son nom l’indique s’appuie sur la carte graphique. Pour l’entraînement comme pour l’utilisation (prédiction), la version GPU est la plus rapide, mais attention, toutes les cartes graphiques ne fonctionnent pas avec Tensorflow GPU.
- Il peut y avoir des problèmes de détection lorsque la personne est trop loin de la caméra où lorsque la vidéo n’est pas de très bonne qualité, l’image analysée par le modèle est alors trop pixellisée.
- De même, le modèle ne détecte pas toujours une personne si deux individus sont trop proches sur la vidéo.
Les ressources pour aller plus loin
Veuillez trouver ci-dessous les ressources mentionnées dans l’article :
- https://medium.com/@techmayank2000/object-detection-using-ssd-mobilenetv2-using-tensorflow-api-can-detect-any-single-class-from-31a31bbd0691
- https://github.com/ahmetozlu/tensorflow_object_counting_api/blob/master/README.md
- https://github.com/opencv/opencv
- https://github.com/tensorflow/models/tree/master/research/object_detection/models
- https://www.tensorflow.org/tutorials/images/transfer_learning
- https://docs.opencv.org/master/dc/da5/tutorial_py_drawing_functions.html